







What will I learn?
- What is ETL?
- What are the various steps involved in ETL?
- What were the main goals of early ETL systems?
- How did ETL systems evolve over the years? What has been the impact of cloud computing on them?
- What are the advantages of modern data management systems over legacy ETL-based systems?
- What are data preparation tools? How are they different from legacy ETL tools?
- What are the advantages of modern data management systems over legacy ETL tools?
- Conclusion
What is ETL? A comprehensive breakdown
ETL, an acronym for Extract, Transform, Load, is the cornerstone process enabling businesses to make sense of their vast data landscapes. Let's take a look at what ETL tools do, and how they have evolved over the years. We will also briefly touch upon on what modern data preparation tools can do and how they improve on legacy ETL processes.
What is ETL?
ETL, which stands for Extract, Transform, Load, is a data integration process from the data warehousing domain that involves extracting data from various sources, transforming it into a format suitable for analysis, and loading it into a central repository. This single, coherent repository is sometimes referred to as the "Single Source of Truth."
What are the various steps involved in ETL?
ETL can be broken down into three distinct stages:
- Extracting data from source systems,
- Transforming the data to meet analytical and other business needs,
- and Loading it into a data warehouse or database.
What are the main goals of early ETL systems?
ETL was introduced in the 1970s, coinciding with the origin and growth of data warehousing. It was originally designed for computational and analytics requirements, and became the de facto method for processing data for data warehousing.
The goal through the process was to bring in data from different sources and transform them to conform to a standard schema or data model.
ETL laid the preparatory steps for data analytics and machine learning, streamlining data through business rules to serve business intelligence and advanced analytics.
It sought to enhance both operational efficiency and user interaction by:
- Retrieving data from older systems.
- Refining data for quality and uniformity.
- Integrating data into a designated database.
Deconstructing the ETL process
How did ETL systems evolve over the years? What has been the impact of cloud computing on them?
The architecture of modern data management is vastly different from the data management that was in practice during the early days of ETL. The modern era of cloud computing, IoT, and AI has seen a quantum leap in the amount of data being recorded by businesses—enterprises have gone from recording millions of transactions to billions of transactions. Modern data management systems have evolved keeping in tune with these changes.
Today, businesses are not just looking at transactional data to make their decisions, but are also identifying and isolating "signals" from the vast troves of data. It is not only about incrementally improving business processes but also about identifying new opportunities.
Cloud computing brought with it solutions like cloud data storage that offered cost-effective storage at scale. Organizations that earlier stored structured data in on-premise data warehouses today have a variety of options for data storage, including data lakes and cloud blob systems. These systems can accommodate unstructured data and often store data in their raw format.
What are the advantages of modern data management systems over legacy ETL-based systems?
Modern data management systems are driven by the need for more flexibility, scalability, and efficiency in data handling.
Just as early ETL systems emerged alongside the data warehousing systems, modern data tools are closely linked with the emergence of new generation data storage systems.
The rapid development of flexible and scalable data storage systems has led to the decoupling of the data movement from data preparation. In effect, the extract and load aspects of ETL has been decoupled with the transformation aspect of data management.
Let us examine this with an example from a modern context. Let us consider a business enterprise that is present in different locations and has many departments. Each department or location handles its data separately. The sales data is stored in a CRM, the employee information is managed in an HR system, and the inventory and related records are recorded in a custom-built system.
Data engineers in the IT department ran ETL processes to extract data from these disparate sources, transform them into a format that is ideal for analysis, and load them to data warehouses.
However, modern data management does not require the help of data engineers or even an IT team to prepare data for analysis. It is possible even for non-technical persons to prepare data in a way they deem fit for their analysis and decision-making.
What are data preparation tools? How are they different from legacy ETL tools?
Data preparation or data wrangling tools, as they are sometimes called, are modern data tools that address the "transformation" part of the conventional ETL cycle. It is also the "content" part of the ETL process where data is being prepared for downstream consumption.
Though they work on the same core principles as early ETL systems, such as mapping schemas between relational databases, computing formulas and loading databases, modern data preparation tools go a lot further.
Where traditional ETL tools relied on data engineers and an IT department to run the processes, modern data preparation tools empower a new set of users to work with data. By way of a user-friendly interface, and by providing visual breakdowns on data quality, smart suggestions, and other visual cues, data preparation today enables even nontechnical users to prepare data.
Modern data preparation tools democratize the process of data transformation by opening up the process of data preparation to nontechnical users with visual cues.
Self-service data preparation tools use visualization and AI-driven recommendations to open the process of data preparation to a new generation of users, including data enthusiasts.
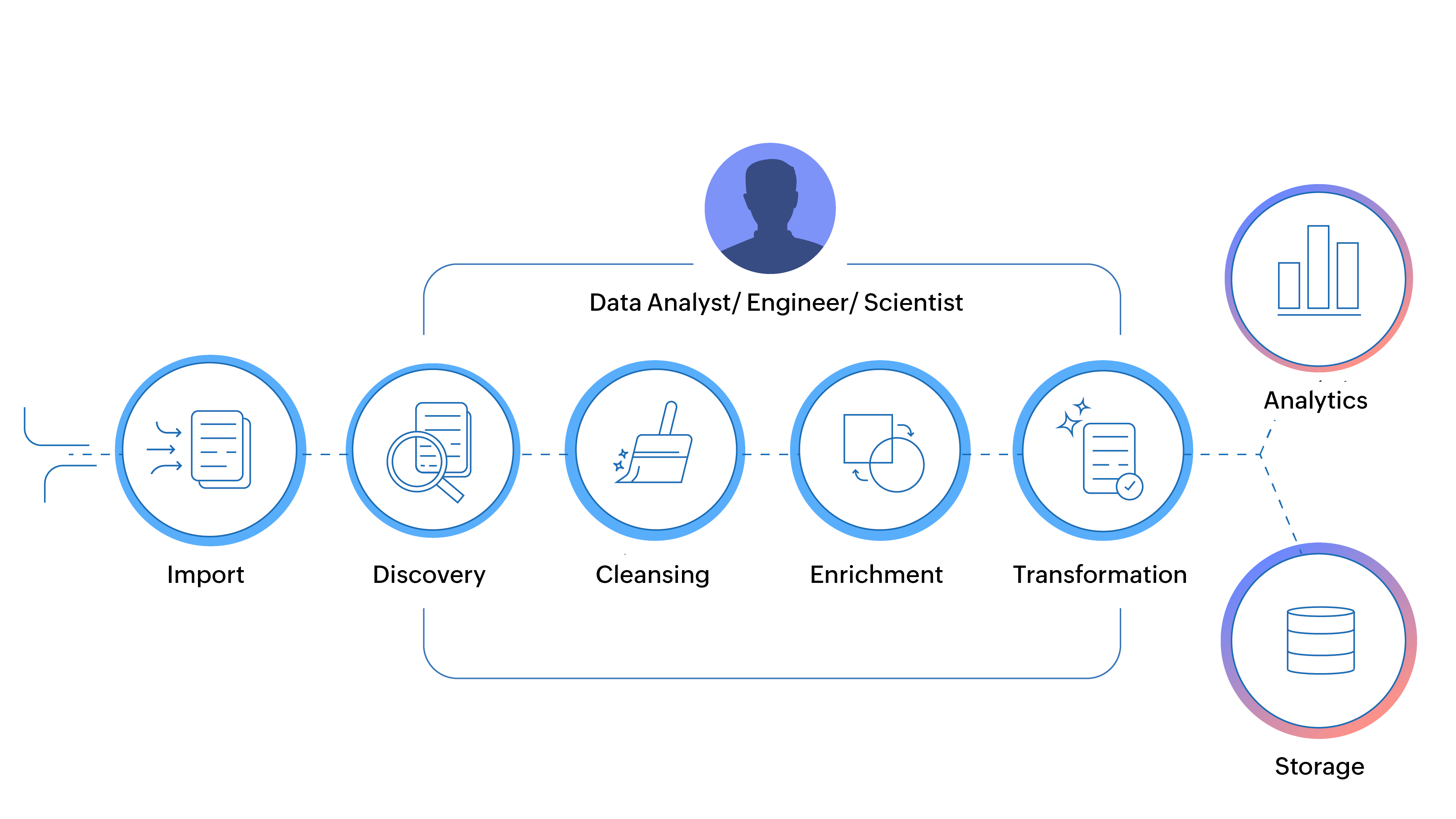
Modern data preparation tools allow users to prepare data in an easy to use interface and leverage modern technologies like artificial intelligence.
What are some of the key benefits of using data preparation tools?
Modern data preparation tools, which form one of the critical parts of the data management workflow today, offer three broad benefits when it comes to data management. Accelerate time to value Reduce operational costs Improve monitoring and governance
Conclusion
When seen at a superficial level, the flow of data through a data management system today remains, in spirit, similar to what happened during the formative years of ETL systems. However, today's process of preparing data has been democratized due to modern tools that provide users with visual cues on how to prepare data easily.